
OpenAI的ChatGPT的推出及其对问题或提示的非常连贯的响应,将大型语言模型(LLM)及其功能推向了公众意识。头条新闻既令人兴奋又令人担忧:它能写一封求职信吗?让人们用一种新的语言交流?帮助学生作弊?通过社交媒体影响选民?让作家失业?
现在,随着谷歌、Meta等公司推出类似模型,研究人员呼吁加强监督。
“我们需要一个新水平的基础设施和工具来为这些模型提供护栏,”斯坦福大学四年级计算机科学研究生EricAnthonyMitchell说,他的博士学位是EricAnthonyMitchell。研究的重点是开发这样的基础设施。
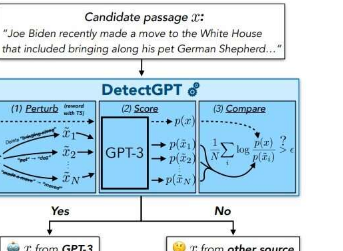
一个关键的护栏将为教师、记者和公民提供一种方法,让他们知道他们何时正在阅读由LLM而不是人类生成的文本。为此,Mitchell和他的同事开发了DetectGPT,上周作为演示和论文发布,它区分了人类和LLM生成的文本。在最初的实验中,该工具在95%的时间内准确识别了五个流行的开源LLM的作者身份。
虽然该工具处于早期阶段,但米切尔希望将其改进到可以造福社会的程度。
“这些语言模型的研究和部署进展迅速,”斯坦福大学计算机科学和电气工程助理教授、米切尔的顾问之一切尔西芬恩说。“公众需要更多工具来了解我们何时阅读模型生成的文本。”
直觉
仅仅两个月前,研究生同学兼合著者亚历山大·哈扎茨基(AlexanderKhazatsky)给米切尔(Mitchell)发短信问道:您认为有办法对一篇论文是否由ChatGPT撰写进行分类吗?这引起了米切尔的思考。
研究人员已经尝试了几种混合效应的通用方法。一种是OpenAI自己使用的方法,涉及用人类和LLM生成的文本训练一个模型,然后要求它对另一个文本是由人类还是LLM编写的进行分类。但是,米切尔认为,要在多个学科领域和语言上取得成功,这种方法需要大量数据进行训练。
第二种现有方法避免训练新模型,而只是使用可能生成文本的LLM来检测其自身的输出。Mitchell说,从本质上讲,这种方法会询问LLM它对文本样本的“喜欢”程度。他所说的“喜欢”并不意味着这是一个有偏好的有感知力的模型。相反,模型对一段文本的“喜欢”是“得分高”的简写方式,它涉及一个数字:根据模型,特定单词序列一起出现的概率。“如果它很喜欢,那可能是模特的。如果不喜欢,那就不是模特。”米切尔说,这种方法效果相当好。“它比随机猜测要好得多。”
但是当Mitchell思考Khazatsky的问题时,他有最初的直觉,因为即使是强大的LLMs也有微妙的、任意的偏见,倾向于使用一个想法的措辞而不是另一个,LLM将倾向于“喜欢”对其输出的任何轻微改写,而不是原来的。相比之下,即使LLM“喜欢”一段人类生成的文本,这意味着它给了它很高的概率评级,该模型对该文本的轻微修改版本的评估也会更加多样化。“如果我们扰乱人类生成的文本,那么模型或多或少喜欢原始文本的可能性大致相同。”
米切尔还意识到,他的直觉可以使用流行的开源模型进行测试,包括那些通过OpenAI的API可用的模型。“计算模型喜欢特定文本的程度基本上就是这些模型的训练方式,”米切尔说。“他们自动给我们这个号码,事实证明这真的很有用。”
测试直觉
为了检验Mitchell的想法,他和他的同事进行了实验,在实验中他们评估了各种公开可用的LLM喜欢人工生成的文本以及他们自己的LLM生成的文本(包括假新闻文章、创意写作和学术论文)的程度。他们还评估了LLM平均喜欢每个LLM和人类生成的文本的100个扰动的程度。当团队为LLM绘制这两个数字与人工生成的文本之间的差异时,他们看到了两条几乎没有重叠的钟形曲线。“我们可以使用那个数字很好地区分文本的来源,”米切尔说。“与仅衡量模型对原始文本的喜爱程度的方法相比,我们得到了更可靠的结果。”
在该团队的初始实验中,DetectGPT在使用GPT3-NeoX(OpenAIGPT模型的强大开源变体)时成功地将人类生成的文本与LLM生成的文本进行了95%的分类。DetectGPT还能够使用原始源模型以外的LLM检测人类与LLM生成的文本,但置信度略低。(截至目前,ChatGPT尚未公开,无法直接测试。)
对检测更感兴趣
其他组织也在研究识别AI编写的文本的方法。事实上,OpenAI上周发布了新的文本分类器,并报告说它在26%的时间内正确识别了AI编写的文本,并且在9%的时间内错误地将人类编写的文本分类为AI编写的文本。
Mitchell不愿意直接将OpenAI的结果与DetectGPT的结果进行比较,因为没有用于评估的标准化数据集。但他的团队确实使用OpenAI的上一代预训练AI检测器进行了一些实验,发现它在英语新闻文章上表现良好,在PubMed文章上表现不佳,而在德语新闻文章上完全失败。他说,这种混合结果对于依赖于预训练的模型来说很常见。相比之下,DetectGPT开箱即用地适用于所有这三个域。
逃避检测
Mitchell说,虽然DetectGPT演示仅公开了大约一周,但反馈已经有助于识别一些漏洞。例如,一个人可以策略性地设计一个ChatGPT提示来逃避检测,例如通过要求LLM以特殊的方式或以看起来更人性化的方式说话。该团队对如何缓解此问题有一些想法,但尚未对其进行测试。
另一个担忧是,使用ChatGPT等LLM来作弊的学生将简单地编辑AI生成的文本以逃避检测。米切尔和他的团队在他们的工作中探索了这种可能性,发现尽管编辑过的文章的检测质量有所下降,但当少于10%–15%的文本时,该系统仍然可以很好地发现机器生成的文本。这些词已被修改。
米切尔说,从长远来看,目标是为公众提供可靠、可操作的预测,以判断文本——甚至文本的一部分——是否由机器生成。“即使模型不认为整篇文章或新闻文章是由机器撰写的,你也会想要一个可以突出显示特别是机器制作的段落或句子的工具,”他说。
需要明确的是,米切尔认为在教育、新闻和其他领域有很多法学硕士的合法用例。然而,他说,“为教师、新闻阅读者和整个社会提供工具来验证他们正在使用的信息的来源一直是有用的,即使在人工智能时代也是如此。”
为法学硕士建立护栏
DetectGPT只是Mitchell为LLM构建的几个护栏之一。在过去的一年里,他还发布了几种编辑LLM的方法,以及一种称为“自毁模型”的策略,当有人试图将其用于恶意目的时,该策略会禁用LLM。
在完成博士学位之前,米切尔希望至少再改进一次这些策略。但现在,米切尔很感激他在12月份的直觉。“在科学界,您的第一个想法很少像DetectGPT那样奏效。我很高兴地承认我们有点幸运。”
该研究发表在arXiv预印本服务器上。